GDPR – Tekniska utmaningar
Om författaren
Anders M Olausson är QA Community Lead på Sopra Steria. Anders arbetar med kvalitetsstrategi och kvalitetscoachning såväl internt som för Sopra Sterias kunder. Han fokuserar på att strategiskt säkra kvalitet i system och företagsmiljöer vilket oftast är en fråga om att skapa samarbeten.
I maj är det två år sedan GDPR trädde i kraft och den här artikeln är ett försök att sammanfatta status och de utmaningar som i vissa fall ännu inte hanterats.
När jag talar med personer om GDPR så har de flesta en mycket negativ syn på lagen. Jag brukar då fråga mer i detalj om varför den ses som negativ, men då blir de oftast mer svävande vilket troligtvis beror på att de inte satt sig in i vad den egentligen innebär.
Ett annat argument är att det är omöjligt att bygga om just deras system så att det följer lagen. Det är naturligtvis inte sant, men det kan i många fall bli väldigt dyrt. Man säger även att man har fått för dåligt med tid på sig vilket inte heller är sant. Nästan allt av det som ses som svårt att anpassa med hänvisning till GDPR gällde redan under PUL som infördes 1998. Många av dessa system började utvecklas långt efter att PUL trädde ikraft och kostnaden för att bli påkommen var i värsta fall en dryg veckas konsultarvode.
Min förhoppning med denna artikel är att ni som läser den ska få ett bättre grepp över hur ni ska hantera GDPR ur en teknisk aspekt och två konkreta tips vill jag ge er redan nu:
- Börja i liten skala och iterera fram en lösning, osäkerheten i vad som i praktiken behöver göras är oftast mycket stor.
- Gör inte problemen större än vad de redan är. Om ni initierar ett nytt projekt eller bygger om ett gammalt system, se till att det blir rätt från början.
Min uppfattning är att GDPR går ut på att:
- Man kan i många fall säga att det är de enskilda individerna som ”äger” sina personuppgifter. Vilket ställer krav på organisationer så att de inte använder dessa utan ett giltigt syfte.
- Organisationerna måste hantera dessa uppgifter på ett sådant sätt att de kan visa att de följer den första punkten och se till att de inte missbrukas, sprids, medvetet eller via intrång till tredje part, eller tas bort.
Jag har personligen svårt att se hur något av detta kan vara problematiskt för ett seriöst företag att ställa sig bakom. Att man har problem med vissa detaljer av GDPR är dock förståeligt, men det är trots allt regler på samma sätt som regler om moms och bokföring. Att hantera dessa utmaningar har även en hel del positiva bieffekter.
Lite mer i detalj:
- Allt som enskilt eller tillsammans med annan data kan identifiera en person räknas som personuppgift.
- Personuppgifter kan ha olika känslighetsgrad vilket man måste anpassa sig till.
- Samtycke från den registrerade räcker ofta inte (eller är inte giltigt). GDPR har få prejudicerande fall, vilket gör att det fortfarande görs olika tolkningar.
När jag för några år sedan började intressera mig för att lösa de tekniska utmaningar som GDPR ställer på IT-system insåg jag tidigt att det kräver många olika kompetenser. Vi som jobbar med att kvalitetssäkra system har ofta merparten av dessa vilket jag kunde kombinera med de grundläggande kunskaper jag har inom juridik. Att jag hade förståelse för juridik, verksamhet, säkerhet, databaser, utveckling, processer, nätverk, utveckling och test gjorde på inget sätt att det blev enkelt. Det gjorde det dock möjligt att kommunicera med de som har spetskompetens inom alla dessa discipliner på deras eget språk.
Att lägga ett juridiskt lager på en ibland dålig kommunikation gör det ännu mer komplicerat. I synnerhet när det gäller en ny lag där det inte finns så mycket juridisk vägledning att luta sig mot. Jag tror inte att IT-branschen skiljer sig från andra men man är ofta enkelspårig i sitt tänkande och när man ställer frågor av typen ”är det tillåtet eller inte” har man ofta svårt att hantera svar av typen ”det beror på”, det vill säga den så kallade gråzonen. Ett exempel på det är att man ofta tror att allt kan lösas med samtycke. Vilken även den första GDPR-boten som utfärdades i Sverige tyder på.
”Viktigast av allt är att man inte förvärrar situationen. Inköp och installationer av nya system samt uppgraderingar kan vara en ”stepping stone” som hjälper oss lösa de utmaningar man har med GDPR.”
Viktigast av allt är att man inte förvärrar situationen. Inköp och installationer av nya system samt uppgraderingar kan istället vara en ”stepping stone” som hjälper oss lösa de utmaningar man har med GDPR.
Den största utmaningen med att lösa de brister man har i sina system rörande GDPR är ofta dålig kommunikation mellan olika delar av IT samt verksamheten. Det är därför ett samarbetsprojekt som varken IT eller verksamhet kan äga själva.
Det är inte bara gamla system som fortfarande bryter mot lagen. Ofta implementeras nya system och projekt där man ibland medvetet gör det, främst för att man inte vet hur man ska göra annars. Det här är vanligt främst i utvecklingsmiljöer då man hävdar att man måste ha all produktionsdata inklusive personuppgifter för att inte missa något. Detta tyder på att man inte har ordentlig kontroll över systemen och/eller hur man ska testa effektivt. (mer om detta under rubriken ”Testdata”)
När man hanterar data som flödar mellan system är det viktigt att testa varje delsystem väl innan man integrerar dem med andra. Så kallade ”end to end”-tester bör användas för att verifiera att man har tänkt rätt under testarbetet, inte för att leta efter fel. På den här nivån kan man inte testa särskilt noggrant då antalet möjliga kombinationer av data och flöden är i det närmaste oändligt stort. Risken är därför stor att om man lägger fokus på dessa tester så kommer man bara att hitta en bråkdel av de fel som finns och de kommer att vara svåra att hitta orsaken till och ibland komplicerade att åtgärda.
Nyttan av att anpassa sina system
De undersökningar som har gjorts tyder även på att de som anpassat sina system har sett andra fördelar. Det gör att man ibland kan se arbetet med GDPR främst som en investering och inte en kostnad.
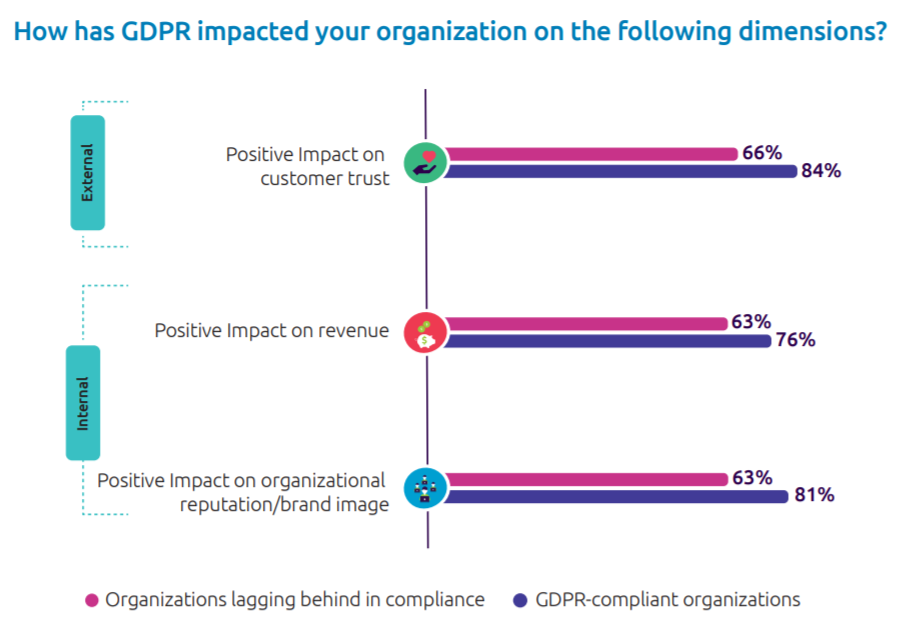
Källa: Capgemeni – Championing Data Protection and Privacy
Det finns några ständigt återkommande argument när jag talar med kollegor och kunder om varför man ännu inte löst GDPR-utmaningarna. Man väntar på prejudicerande domar och/eller på att kraven på GDPR-efterlevnad ska mildras. De påstår att det är omöjligt för dem att bygga om sina system så att de följer GDPR, alternativt att det skulle bli oförsvarligt dyrt. Man säger även att man planerar för att hantera det vilket man fått höra kommer att ge dem en lägre bot om myndigheterna uppmärksammar det.
Ju längre man väntar, desto dyrare kommer det troligtvis att bli och att lagen ska mildras finns det inget som tyder på, tvärtom.
Enligt en rapport från Capgemini Research Institute trodde 70% av de svenska företagen i april 2018 att de skulle vara GDPR-anpassade i juni samma år. Ett år senare visade det sig att endast 18% faktiskt är det. Det här är baserat på självskattning så kanske är det faktiska resultatet ännu sämre.
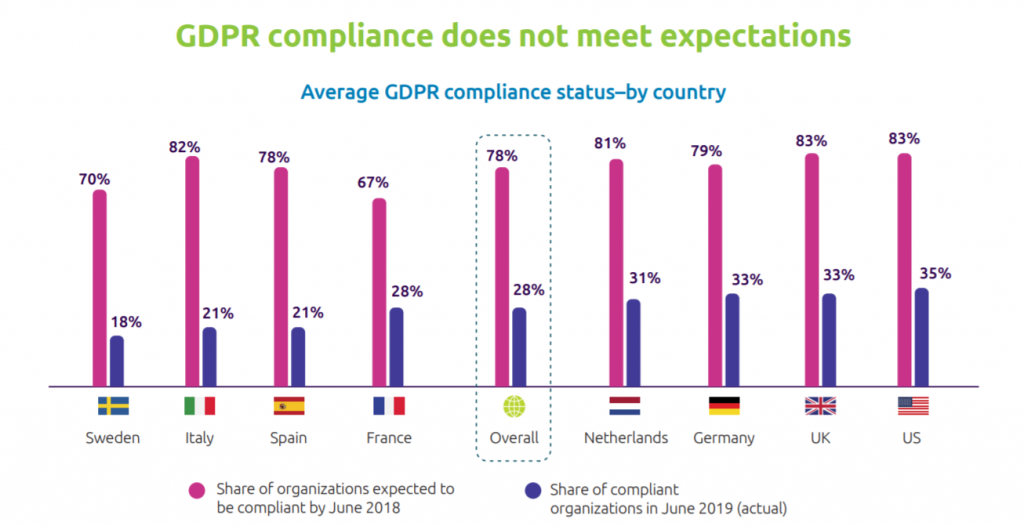
Källa: Capgemeni – Championing Data Protection and Privacy
Dataskydd är inte unikt för EU utan det växer sig allt starkare runt om i världen. Till exempel så trädde California Consumer Privacy Act (CCPA)i kraft 1 januari 2020 och påminner i flera avseenden om GDPR. Dessa lagar påverkar svenska företags möjlighet att göra affärer med andra länder på samma sätt som GDPR påverkar möjligheterna att göra affärer inom EU. Att lösa utmaningarna med GDPR förbereder oss därför för hur man anpassar sig till andra länders lagar och förordningar.
Hur blir man ”compliant”
Hur vet vi om vi följer lagen och hur ska vi lösa eventuella brister i våra system? Först måste vi bryta ner dem i delar och analysera såväl helheten som enskilda system enligt följande:
1. Funktion
Följer man de regler som ställs vilket ställer krav på arkitektur, arbetssätt etc?
2. Säkerhet
Reglerna säger att man ska skydda data, men de säger inte i detalj hur – eller i vart fall inte på en detaljnivå som en tekniker normalt önskar. Den föreslagna e-Privacy-förordningen (EPR), ska delvis reglera detta för elektronisk kommunikation vilket man bör vara uppmärksam på.
3. Utvecklingsmiljöer
Förutom att reglerna ställer samma krav på utvecklingsmiljöerna så finns det ytterligare faktorer att hantera. (Mer om detta under ”Utvecklings-/testmiljöer”)
Funktion
Jag tänker inte gå in på vad GDPR innebär i detalj, jag är ingen jurist och det här är en advokatbyrås blogg så jag överlåter det till Delphi, du kan hitta en mängd blogginlägg om GDPR här. Kort sammanfattat så måste man veta vilka personuppgifter som sparas och skälen till att de samlats in. Man måste ha möjlighet att skapa registerutdrag, att korrigera felaktigheter och i vissa fall ta bort uppgifter. Uppgifter som det inte längre finns skäl att spara, ska tas bort. Sådana uppgifter som behöver sparas av andra skäl, t. ex. bokföring, får inte tas bort.
Vilka krav ställer det på systemen och hur man bör hantera dessa utmaningar?
Det kan hända att man har personuppgifter för miljontals individer spridda i sina system. Det säger sig självt att det är omöjligt att hantera dem manuellt när någon hör av sig och vill ha ett registerutdrag.
Man bör därför se över sina system och konsolidera uppgifter till så få system som möjligt. Man bör även ställa sig frågan om man behöver alla dessa uppgifter? Det har nästan varit ett mantra från i synnerhet sälj- och marknadsföring att ”de är bra att ha”. Man bör även tänka på att allt ett system samlar in måste administreras, det kan även skapa komplexa beroenden i system och mycket annat. Dessa uppgifter bör sedan kunna läsas av andra system, men helst inte kopieras.
När en person begär att få ett registerutdrag så är det viktigt att det hanteras säkert. Det har visat sig allt för enkelt att ringa eller maila utan att behöva styrka sin identitet. Även för det här måste det finnas en process för att uppgifterna inte ska hamna i fel händer. Denna artikel belyser på ett bra sätt hur enkelt det kan vara att få ut uppgifter utan att styrka sin identitet.
Masterdata är en term som ofta används när man talar om att konsolidera och skapa relationer mellan uppgifter i olika system. Det behöver inte betyda att man samlar allt på samma ställe, däremot kan man skapa relationer mellan databaser så om man uppdaterar på ett ställe så slår det igenom överallt. Om det är en konflikt så är det den källa som är ”viktigast” som är rätt, alternativt så varnas man och får hantera det manuellt. Att ”ta kontroll”, rensa och konsolidera det data man har i sina system i samband med att man hanterar GDPR är att rekommendera.
Facebook är ett lysande exempel på hur man kan hantera registerutdrag ur ett GDPR-perspektiv. Du kan själv läsa alla uppgifter de har om dig, du kan ändra felaktigheter och du har möjlighet att ladda ner allt i en fil. De har automatiserat sitt flöde vilket innebär att de inte behöver hantera registerutdrag manuellt. De branscher som måste kunna portera kunder till andra aktörer kommer att få det svårt om de inte automatiserar dataflödet.
Säkerhet
Säkerhet i IT-system är ofta eftersatt, troligtvis för att det är så komplext, men grunderna för hur man bör tänka är inte så svåra att förstå. I och med GDPR är det inte bara dumt och en risk för verksamheten att inte göra tillräckligt, utan det är även olagligt och kan ge höga böter.
Det är omöjligt att bygga ett helt säkert system. Inte ens system som är helt avskilda från internet kan betraktas som helt säkra. Man måste även se på säkerhet som en lager på lager-lösning och vara medveten om att brister i en enda del kan äventyra allt.
För att citera Ciscos fd VD, John Chambers “There are two types of companies: those that have been hacked, and those who don’t know they have been hacked.”
Att det är olagligt att hantera personuppgifter ovarsamt är nog ingen nyhet för någon med tanke på all den press som följt den senaste tiden på flera uppmärksammade incidenter och hur lätt det har varit att få ut personuppgifter. Men färre känner till hur oerhört dyrt det kan bli för företag som blir attackerade, där det på senare tid finns ett antal exempel globalt på attacker som har kostat hundratals miljoner kronor att åtgärda.
Norsk Hydro har varit väldigt transparenta i hur de hanterade den attack som de utsattes för i mars 2019. En attack som enligt dem själva kostade dem någonstans mellan 550 och 650 miljoner norska kronor. Hur de hanterade detta kan ses som ett skolboksexempel på hur man bör hantera en sådan attack, men om de hade säkrat upp systemet innan så hade det kostat en bråkdel av denna summa.
Man kan dela upp säkerhet på flera sätt men man bör tänka förebyggande, reaktivt samt analys och uppföljning.
Förebyggande
Vad man kan göra för att se till att incidenter inte uppstår och se till att man står förberedd när det trots allt händer. Denna kategori kan i sin tur delas upp i underkategorierna tekniskt skydd och kunskaps-/processförberedelse.
Tekniskt skydd
I denna kategori har man brandväggar, antivirusskydd, behörighetskontroller, segmentering och mycket annat och här finns det ofta en övertro på att om man har någon eller några av dessa på plats så har man gjort tillräckligt.
Kunskaps-/processförberedelse
I denna kategori hittar man planer för vad man ska göra om något händer, t. ex. ett intrång. Det innefattar även utbildning av personalen i säkerhetsmedvetande. Så kallad ”social engineering”, där man genom att uppträda trovärdigt lurar någon i personalen och därmed kringgår det tekniska skyddet, är oerhört svårt att skydda sig mot på annat sätt. Det är även vanligt att personalen kringgår det tekniska skyddet på olika sätt då de inte förstår varför det finns.
Exempel: Det finns ofta goda skäl till att organisationen blockerar fildelningstjänster som Dropbox och Google Drive. Men risken är då stor att användarna istället skickar filer i e-post eller bär omkring okrypterade USB–minnen vilket oftast är en allvarligare risk. En IT-avdelning måste prioritera användarnas behov vilket ofta betyder att erbjuda alternativa lösningar till de man anser osäkra, annars är risken stor att delar av personalen medvetet går runt blockeringar för att de inte förstår varför de finns. Det kan skapa större säkerhetsrisker än de man förhindrar.
Reaktivt
Vad man gör när det händer för att så snabbt som möjligt agera, förhindra och kanske återställa miljön.
1997 jobbade jag på Göteborgs universitet och upptäckte att vi hade intrång i en server eftersom filer försvann under en livesändning. Min reaktiva lösning var att springa in i serverrummet och slita ut den ingående nätverkskabeln. Det var en lördag på en enskild institution så ingen annan verksamhet påverkades. Om jag hade gjort detta för ett stort företag med t.ex. stora kassaflöden kunde kostnaderna ha blivit oerhört stora.
Att jag upptäckte att filer började försvinna var en ren slump men man måste bevaka på ett sätt så att man uppmärksammar ”udda” händelser.
”Det är nödvändigt att bevaka system och upptäcka intrång när de sker. Den genomsnittliga tiden från incident till upptäckt är i Skandinavien ca 300 dagar och kostnaden för dessa är direkt relaterade till tiden mellan incident och hantering.”
Det är nödvändigt att bevaka system och upptäcka intrång när de sker. Den genomsnittliga tiden från incident till upptäckt är i Skandinavien ca 300 dagar och kostnaden för dessa är direkt relaterade till tiden mellan incident och hantering. När en incident sker måste man ha en plan för vad man ska göra. Dessa påverkar även det tekniska skyddet, t.ex.- att man p.g.a. den riskbedömning som gjorts segmenterar nätverket. Om man placerar kontorsmiljöerna i ett annat segment än betalningslösningen så betyder inte det per automatik att intrång i det ena äventyrar det andra. Att stänga ner t.ex. en betalningslösning, bara för att man har ett intrång någon annanstans i systemet, kan bli oerhört dyrt och kan kosta mer än vad intrånget skulle ha kostat.
Analys och uppföljning
Man bör även ha en policy och rutiner för hur incidenter hanteras och följs upp och dokumenteras, främst för att förebygga att det händer igen.
Om personuppgifter exempelvis har använts i strid mot GDPR eller om ett intrång har skett så att detta utgör en s.k. incident måste man som huvudregel rapportera detta till Datainspektionen inom 72 timmar efter upptäckt, och om incidenten ses som allvarlig även rapportera till berörda individer. För detta behövs rutiner.
Utvecklings-/testmiljöer
När man talar om testmiljöer och GDPR har fokus legat på produktionsdatabaser och hur man maskerar (anonymiserar/pseudonymiserar) personuppgifter för att använda dem i testmiljöer, och det är här de flesta kör fast.
”Men varför kan vi inte bara begära samtycke i våra användaravtal och använda personuppgifter?” Alla de bestämmelser som reglerar personuppgifter i produktionsmiljöer gäller även här, men man behöver dessutom ett specifikt skäl att hantera dem i testmiljöer. Dessutom – ett samtycke behöver vara specifikt och frivilligt och kan alltid tas tillbaka. Hur hanterar man ett sådant tillbakatagande i en testmiljö på ett praktiskt sätt?
Dessa miljöer innefattar utvecklares laptops, testmiljö för specifika system, stagemiljöer där man testar system tillsammans o.s.v.. Det är heller inte ovanligt att man arbetar med flera olika utvecklingsgrenar (branches) samtidigt.
Att kontrollera hur personuppgifter används på alla dessa ställen och även upprätthålla säkerheten är väldigt svårt och ibland omöjligt. Även om man kan motivera det enligt lag, kan detta innebära att det blir alldeles för komplicerat och därigenom dyrt. Det är inte ens säkert att vi vill använda produktionsdata även om det är lagligt och inte innebär problem, vilket vi snart ska gå in på.
Analysera
Innan man ger sig på arbetet med att skapa testdatabaser måste man göra en ordentlig analys, inte bara baserad på om det är personuppgifter eller ej. Man måste även förstå hur systemen behandlar uppgifterna, om dess innehåll har betydelse för testerna, hur de ”hänger ihop”, inte bara med det specifika systemet utan även med andra de kommunicerar med.
Detta arbete kan sällan utföras av en person utan det är oftast ett lagarbete mellan olika kompetenser såsom verksamhet, jurister, databasexperter, utvecklare och testare. Man kan heller inte räkna med att det blir rätt vid första försöket utan man får räkna med att detta är en iterativ process.
Om det finns känsliga och konfidentiella uppgifter i dessa databaser måste man även tänka på säkerheten kring dessa processer.
När man har gjort den första analysen är det dags att bestämma om man ska anonymisera/pseudonymisera eller om man ska skapa fiktiva data utan koppling till produktionsdata. Fullständig anonymisering är dessutom ofta, givet definitionen av vad som är en personuppgift, ganska svår att åstadkomma utan att data blir värdelös.
Använda produktionsdata i testmiljöer
Det främsta argumentet man hör för att använda produktionsdata är att det är bara där som man vet hur data kommer att se ut.
Kritik mot att använda produktionsdata i testsyfte är bl.a.
- Det innehåller fel man inte känner till
- Det innehåller inga eller fel typ av fel (man behöver fel för att testa att det inte skapar problem om det uppstår i produktionsdatabasen)
- Det är inte tillräckligt utmanande med ovanliga tecken, höga/låga värden osv
- Det är inte anpassat för det man behöver testa
Alternativet till att använda produktionsdata är att skapa detta data själv från algoritmer och listor.
Att generera data (syntetisera) gör det lättare att anpassa data för tillfället vilket inte alltid innebär att man vill ha mycket data. I början kan det vara lämpligt att ha lite och felfritt data och efterhand använda mer och komplicerat som är anpassat till de typer av tester som man behöver utföra. Testdatabaser bör inte vara statiska utan man bör använda sådant som underlättar testarbetet.
System i produktion
Om man inte har byggt systemet med fiktivt data kan det ibland vara svårt att byta ut befintligt data och ersätta det med fiktivt. Det har främst följande orsaker:
- Komplicerade beroenden inom systemet och otydliga krav på enskilda fält, t.ex. hur långa textsträngar får vara, begränsningar av formateringen (t.ex. hur man skriver in personnummer) o.s.v., som inte alltid är dokumenterade.
- Brister i förståelsen av systemen samt övergripande dokumentation.
- Systemen är inte tillräckligt väl testade var för sig, så man vet inte hur andra system klarar förändringar man gör i ett annat som är integrerat.
Det här gäller främst för enskilda system. När det gäller integrationer mellan system så läggs ytterligare dimensioner av komplexitet på toppen och att man inte har hanterat dessa är oftast skälet till att de flesta inte lyckas med att anonymisera eller syntetisera fungerande testdatabaser.
Det vanligaste felet med integrationer är att de endast testats med data som ”ska fungera” och man vet därför inte hur de hanterar data som utmanar systemet t.ex. genom komplexitet, fältlängd och felaktigheter.
Att förstå hur man ska testa data i system är även viktigt under krav-, upphandlings- och utvecklingsfaserna. Om ett system är svårt att testa så blir det svårt att garantera kvalitet och dyrt att underhålla.
”Att förstå hur man ska testa data i system är även viktigt under krav-, upphandlings- och utvecklingsfaserna. Om ett system är svårt att testa så blir det svårt att garantera kvalitet och dyrt att underhålla.”
Sammanfattning
Som jag skrev redan i inledningen så är det främst två saker ni bör tänka på:
- Börja i liten skala och iterera fram en lösning, osäkerheten i vad som i praktiken behöver göras är oftast mycket stor.
– Se till att säkra varje del innan ni integrerar med andra.
- Gör inte problemen större än vad de redan är. Om ni initierar ett nytt projekt eller bygger om ett gammalt system, se till att det blir rätt från början.
– Det är ett samarbetsprojekt vilket kräver kunskaper inom många olika kompetenser.
– Jag vill främst lyfta fram säkerhet då det är svårt att applicera det på en redan implementerad lösning och test.
Jag hoppas att den här artikeln ska ge dig en bättre inblick i hur man ska hantera den utmaning som GDPR ställer på oss och att det finns mycket positivt i att få bättre kontroll över våra system.
Relaterat innehåll